 目录
目录Python全系列 教程
3567个小节阅读:5929.2k
目录


鸿蒙应用开发
C语言快速入门
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
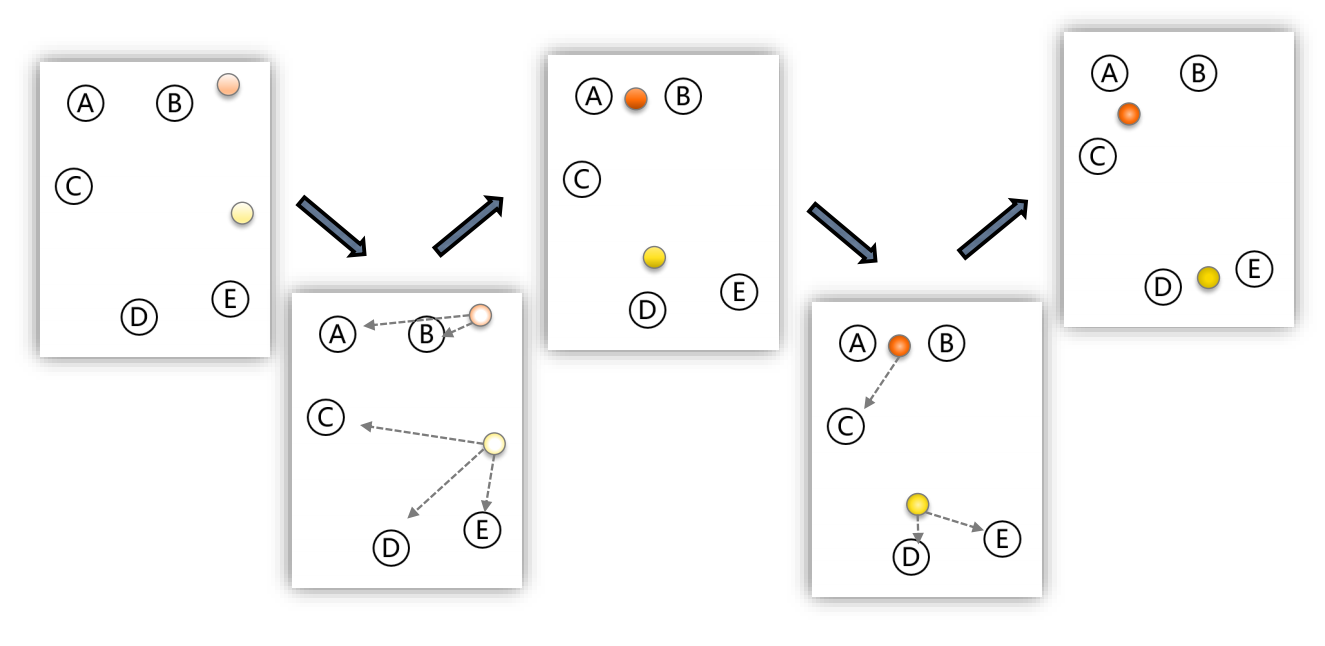
K-Means聚类也称快速聚类,它有效解决了其他聚类分析(例如层次聚类)执行效率低下的问题。因此,K-Means聚类是目前应用最为广泛的聚类分析方法。
指定聚类数目K
确定K个初始类中心点
根据距离最近原则进行分类
重新确定K个类中心点
判断是否已经满足终止聚类分析的条件
上述两个条件中任意一个满足则结束聚类,如果均不满足,则回到第三步
对地区进行K-Means聚类分析,要求分成3类,初始类中心点由SPSS自行确定
选择菜单【分析】----> 【分类】----> 【K-均值聚类】
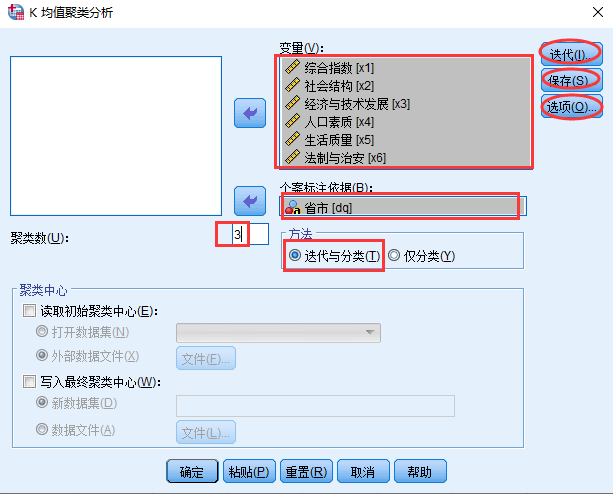
选定参与K-Means聚类的变量到【变量(V)】框中,选择一个字符串型变量作为标记变量到【个案标注依据(B)】框中。标记变量将大大增强聚类分析结果的可读性。在【聚类数(U)】框中输入聚类数目,在【方法】框中指定聚类过程是否调整类中心点。
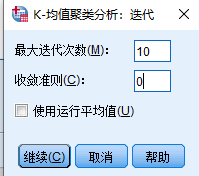
点击【迭代(I)】按钮确定终止聚类的条件
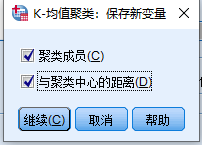
点击【保存(S)】按钮,将聚类分析的部分结果以SPSS变量的形式保存到数据编辑器窗口中
点击【选项(O)】按钮,确定输出哪些分析结果
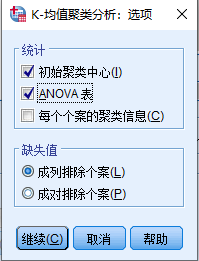
点击“确定”,分析结果如下
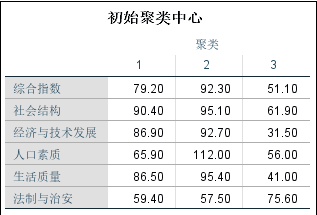
上表展示了3个类的初始类中心点的情况

上表展示了3个类中心点每次迭代时的偏移情况
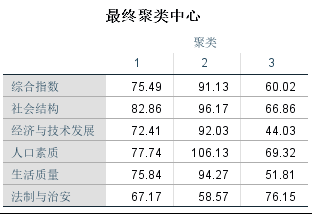
上表展示了3个类的最终类中心点的情况
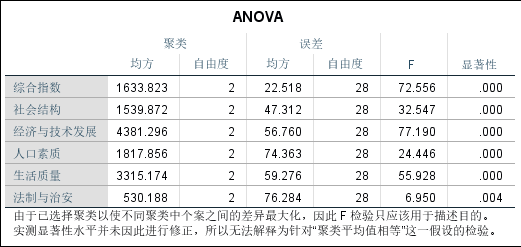
ANOVA表中的内容表示以聚类分析产生的类为控制变量,以聚类变量为观测变量进行单因素方差分析。上表各数据项的含义依次为组间方差、组间自由度、组内方差、组内自由度、F统计量的观测值以及对应的概率P值。该表显示各指数的总体均值在3类中有显著差异,说明目前的聚类是合理的。
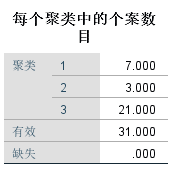
上表展示了3个类的类成员数量。
1. 关于K-Means聚类分析,下列说法正确的是_______
A K-Means聚类不常用
B 需要指定聚类数目K
C 执行效率低下
D 以上说法均不正确
2. K-Means聚类分析的菜单选项是___:
A 【分析】----> 【回归】----> 【线性】
B 【分析】----> 【相关】----> 【距离】
C 【分析】----> 【分类】----> 【K-均值聚类】
D 【分析】----> 【相关】----> 【双变量】
1=>B 2=>C