 目录
目录Python全系列 教程
3567个小节阅读:5929k
目录


鸿蒙应用开发
C语言快速入门
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
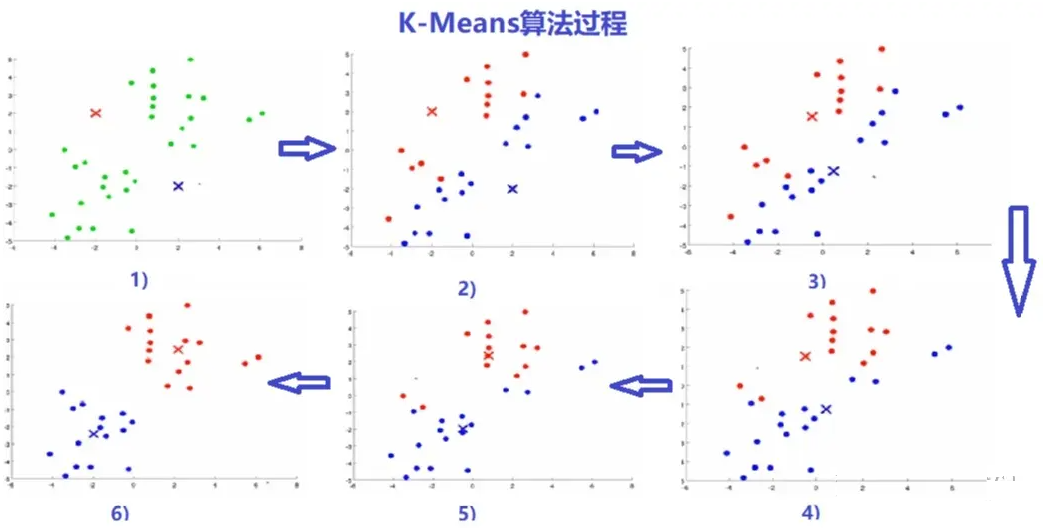
K-Means是聚类算法中最常用的一种,是一种迭代求解的聚类分析算法;聚类是一种
无监督学习,事先并不知道分类标签是什么,它能够将具有相似特征的对象划分到同一个集
合(簇)中。簇内的对象越相似,聚类算法的效果越好。
从样本中随机选择K个点——聚类中心(也可以随机生成K个并不存在于原始数据中的样
本点作为初始聚类中心)
簇分配:遍历每个样本,然后根据每一个点是与红色聚类中心更近,还是与蓝色聚类中心更近,来将每个数据点分配给K个聚类中心之一
根据聚类结果,重新计算k个簇各自的平均值(Means)位置,将该平均值位置作为该簇新的聚类中心
不断重复迭代上述的(2)与(3)两个步骤,直到聚类中心点的变化很小,或者达到指定的迭代次数
注意:
对于聚类数量的选择(参数K的选择),没有一个统一的选择方法,可以根据业务需要选择
CH指标:同时考虑了各个簇之间的分离程度与簇内部的分离程度,来衡量聚类效果。CH分数越高,说明聚类效果越好
xxxxxxxxxxfrom sklearn.metrics import calinski_harabasz_score# 分数越高,聚类效果越好calinski_harabasz_score(X,y_pred)1. 关于KMeans算法,下列说法正确的是:
A KMeans是一种有监督学习
B K-Means属于聚类算法中的一种
C KMeans聚类数量的选择越少越好
D CH分数越高,聚类效果越差
2. 关于KMeans的损失函数,下列说法正确的是:
A KMeans损失函数是每个数据点与其所关联的聚类中心点之间的平均距离
B 最大化损失函数可以帮助k-means找到更好的簇
C KMeans损失函数与线性回归的损失函数是一样的
D 以上说法均不正确
1=>B 2=>A