 目录
目录Python全系列 教程
3567个小节阅读:5929.9k
目录


鸿蒙应用开发
C语言快速入门
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night

有的页面反爬技术比较高端,一时破解不了,这时我们就是可以考虑使用selenium来降低爬取的难度。
问题来了,如何将Scrapy与Selenium结合使用呢?
思考的思路: 只是用Selenium来帮助下载数据。因此可以考虑通过下载中间件来处理这块内容。
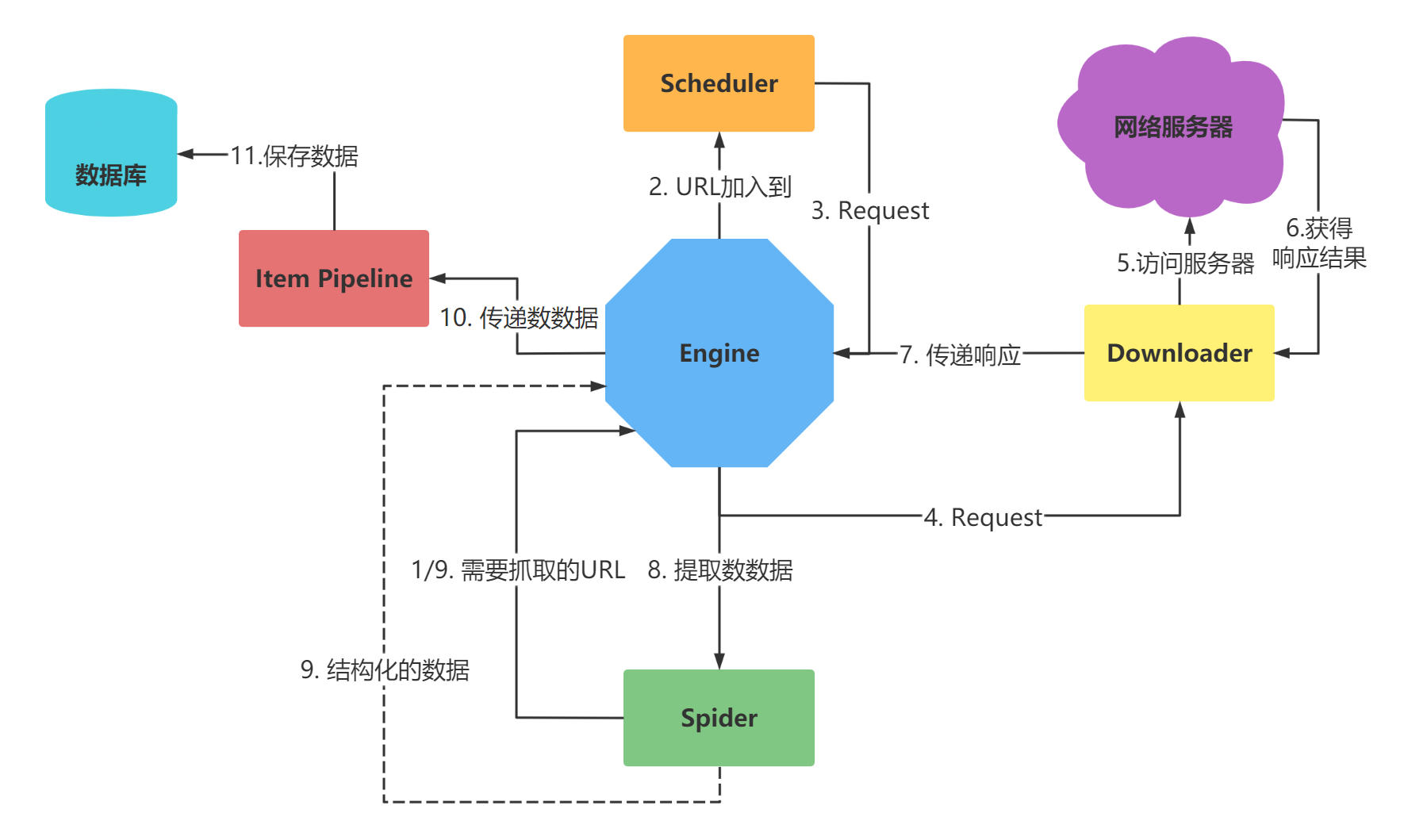
具体代码如下:
Spider文件
xxxxxxxxxx@classmethod def from_crawler(cls, crawler, *args, **kwargs): spider = super(BaiduSpider, cls).from_crawler(crawler, *args, **kwargs) spider.chrome = webdriver.Chrome(executable_path='../tools/chromedriver.exe') crawler.signals.connect(spider.spider_closed, signal=signals.spider_closed) # connect里的参数 # 1. 处罚事件后用哪个函数处理 # 2. 捕捉哪个事件 return spider
def spider_closed(self, spider): spider.chrome.close()middlewares文件
xxxxxxxxxxdef process_request(self, request, spider): spider.chrome.get(request.url) html = spider.chrome.page_source return HtmlResponse(url = request.url,body = html,request = request,encoding='utf-8')