目录
目录Python全系列 教程
3567个小节阅读:5930.4k
目录


鸿蒙应用开发
C语言快速入门
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
因子分析是基于相关关系而进行的数据分析技术,是一种建立在观测数据基础上的降维方法。 因子分析是用来寻找那些隐藏在可测变量中的,无法直接观察到的,却影响或支配可测变量的潜在因子;并估计潜在因子对可测变量的影响程度以及潜在因子之间的关联性的一种多元统计分析方法。
因子分析的目的 理论上讲:研究原始变量的内部关系,简化原变量的内部结构,分析变量中存在的相关关系。
因子分析的基本思想
根据变量间相关性的大小把变量分组,使得同组内的变量之间的相关性(共性)较高,并用一个因子来代表这个组的变量,而不同组的变量相关性较低(个性)。
导入数据


点击“确定”,在输出窗口中查看输出结果:
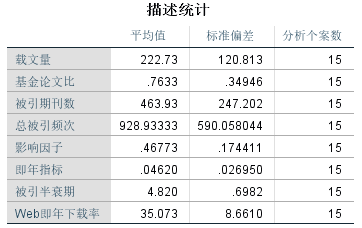
从描述统计中可以看到各个变量的平均值,标准偏差及分析个案数。
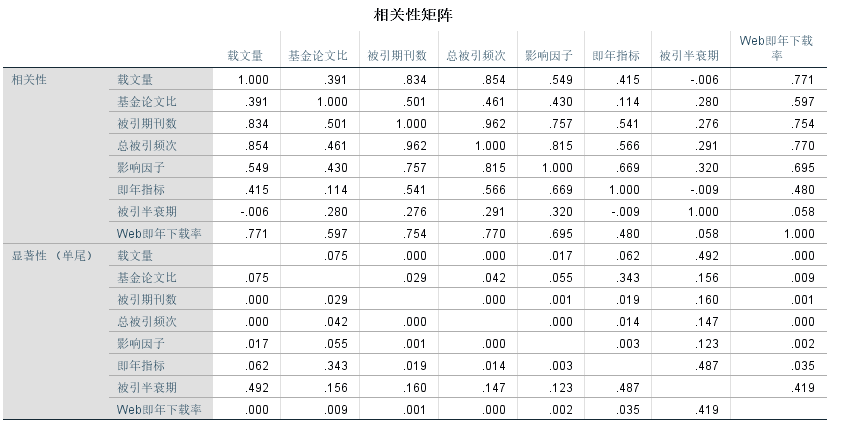
从相关性矩阵中可以看到,每个变量与每个变量之间的相关性高。如从表中可以看到载文量与基金论文比的相关系数是0.391。
从显著性值可以看每个变量与每个变量之间是否显著相关。如载文量和基金论文比的显著性0.075>0.05,说明这两个变量相关性不显著。而载文量和被引期刊数的显著小于0.05,说明载文量和被引期刊数有显著性相关。从表中发现大多数显著性都是小于0.05的,说明大多数变量之间相关性显著。

KMO 检验统计量是用于比较变量间简单相关系数和偏相关系数的指标。主要应用于多元统计的因子分析。KMO 统计量是取值在 0 和 1 之间。0.9 以上表示非常适合;0.8 表示适合;0.7 表示一般;0.6 表示不太适合;0.5 以下表示极不适合。
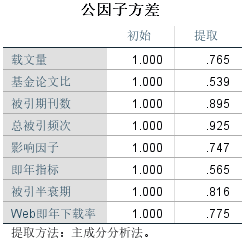
从公因子方差表中可以看到提取值都比较高,表明变量中大部分信息能被因子所提取,说明因子分析结果有效。

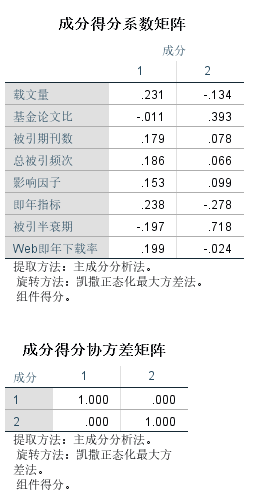
总方差解释图表,也称主成份列表 ,是一个非常重要的表格。一个因子所解释的方差比例越高,这个因子包含原有变量信息的量就越多。第一个成分的初始特征值为4.864能解释的方差比例为60.804%,第二个特征值为1.163,能解释的方差比例为14.541。其余四个成分都小于1,说明这几个成分的解释力度还不如直接引入原变量大。这七个变量只需要提取出头两个成分即可。
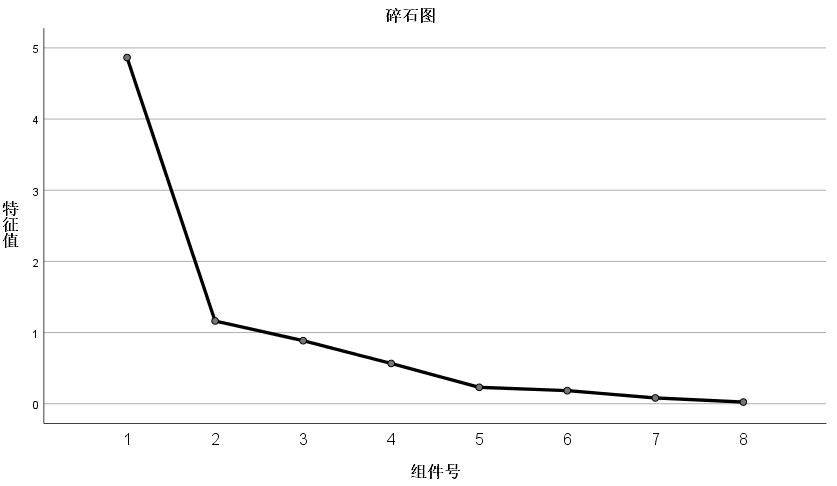
碎石图中,从第二个成分以后的特征值就降得非常低。第二个成分就是这一图形的“拐点”。在这一实例中,只需要提取两个主要成分就行了。
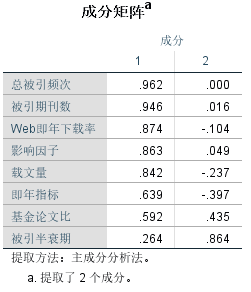
表中列出未使用旋转方法时使用因子能解释的各个变量的比例(各变量的信息被主成份提取了多少)。
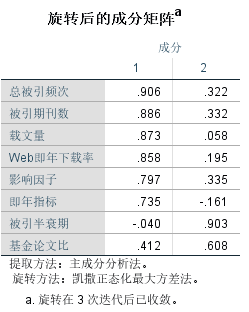
表中列出了使用旋转方法后因子能解释的各个变量的比例。和上面未旋转对比可以看出,旋转后,原先较大的比例值仍然大,较小的比例则变得更小。
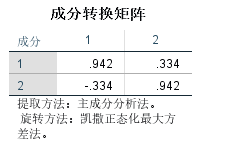
成分转换矩阵表,用来说明旋转前后主成份间的系数对应关系。

从旋转后的空间中的组件图中可以看到,被引半衰期和基金论文比属于一类成分,其余属于另外一类