 目录
目录Python全系列 教程
3567个小节阅读:5931.5k
目录


鸿蒙应用开发
C语言快速入门
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
前面讲解的二元logistic回归分析仅适合因变量Y只有两种取值(二元logistic)的情况,如:死亡或者生存,男性或者女性,有或无,是或否的情况。
当因变量Y具有两种以上的取值时,就要用多元logistic回归分析。多元Logistic分析可以应用到各个领域,比如社会学、经济学、医疗和农业研究等多个领域。如不同阶段(初一、初二、初三)学生视力下降程度。不同龋齿情况(轻度、中度、重度)下与刷牙、饮食、年龄的关系等。
示例:该假设数据文件涉及关于早餐喜好的民意调查,该调查记录了参与者的年龄、性别、婚姻状况以及生活方式是否积极,每个个案代表一个单独的响应者。
调查机构想搞清楚是什么影响着受访人每天吃什么早餐。因变量“早餐选择”包括(1=早餐吧、2=燕麦类、3=谷物类),自变量暂定年龄、婚姻状况以及生活方式。
导入数据
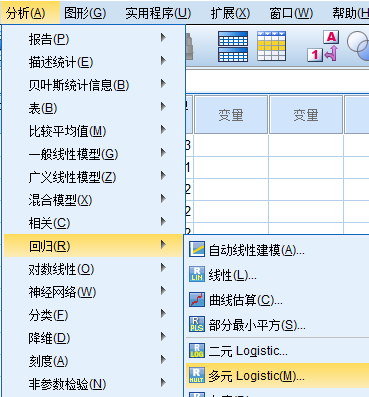
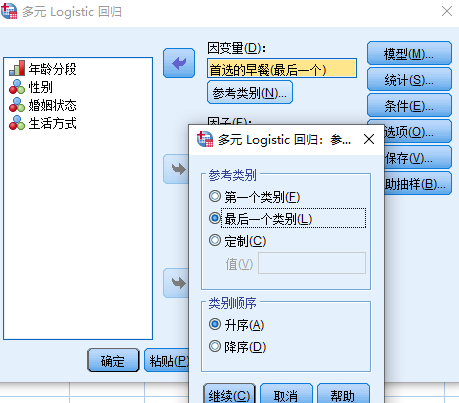
在打开的多元Logistic回归窗口,选择首选的早餐到“因变量”中。点击“参考类别”,默认勾选的是最后一个类别,指以因变量和自变量的最后一个分类水平为参照,用其他分类依次与之对比,考察不同水平间的倾向。
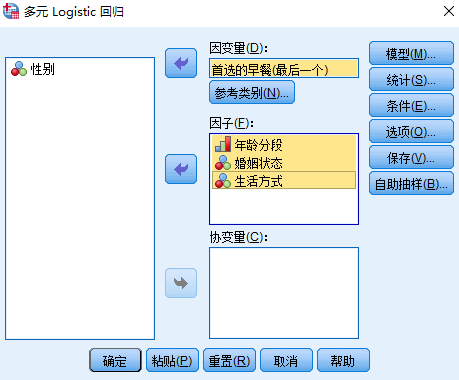
选择年龄、婚姻状况以及生活方式选入“因子”
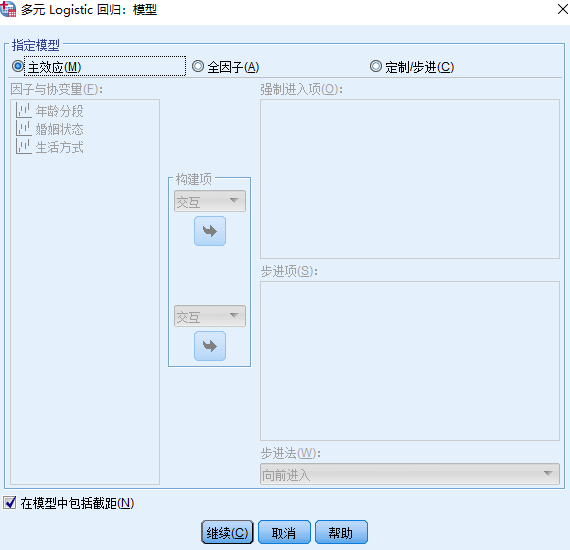
主面板中,点击【模型】按钮,打开【多元logistic回归:模型】对话框,勾选【主效应】,本例主要考察自变量年龄、生活方式、婚姻状况的主效应,暂不考察它们之间的交互作用,然后点击【继续】。
主面板中,点击【统计】按钮,设置模型的统计量。主要【伪R方】【模型拟合信息】【分类表】【拟合优度】这几项必选,其他可以默认不勾选。这些参数主要用于说明建模的质量。
在“条件”按钮和“选项”按钮中取默认值就好
最大迭代次数必须是小于等于100的整数。
点击“确定”查看输出结果:
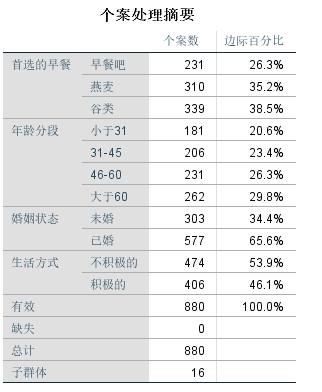
个案处理摘要表,列出因变量和自变量的分类水平及对应的个案百分比。建议在此表主要读取变量分类水平的顺序,比如自变量“年龄段”,第一个分类是“低于31岁”,第二个分类是“31-45”,第三个分类是“45-60”,第四个分类是“60岁以上”,尤其是看清楚最后一个分类,因为我们前面参数设置时要求是以最后一个分类最为对比参照组的。
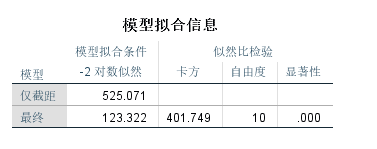
模型拟合信息表,读取最后一列,显著性值小于0.05,说明模型有统计意义,模型通过检验。
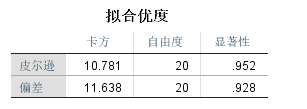
拟合优度表,原假设模型能很好地拟合原始数据,最后一列皮尔逊卡方显著性值0.952,概率较大,原假设成立,说明模型对原始数据的拟合通过检验。
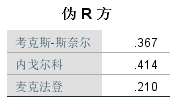
伪R方表,依次列出的3个伪R方值(类似于决定系数)均偏低,最高0.4,说明模型对原始变量变异的解释程度一般,还有一部分信息无法解释,拟合程度并不是很优秀。
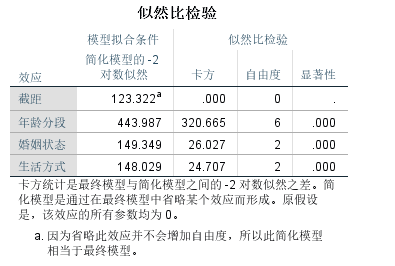
模型似然比检验表,我们能看到最终进入模型的效应包括截距、年龄、婚姻状况、生活方式,而且最后一列显著性值表明,三个自变量(影响因素)对模型构成均有显著贡献,研究它们是有意义的。
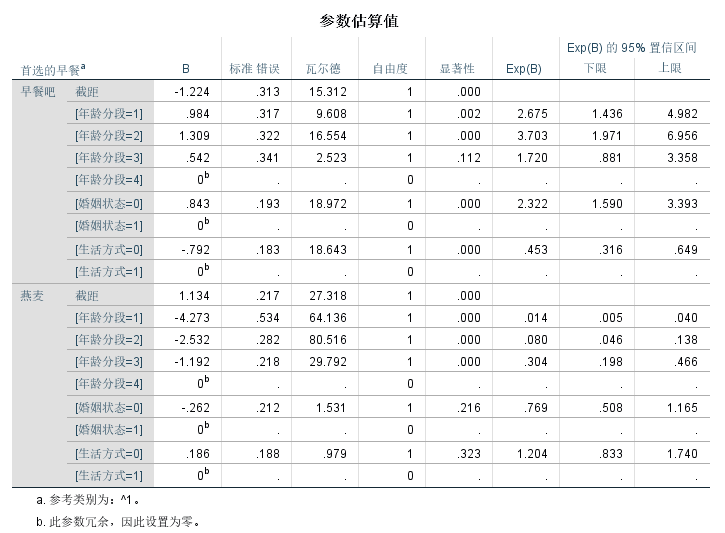
参数估计表,列出自变量不同分类水平对早餐选择的影响检验,是多元logistic回归非常重要的结果。
第二列B值,即各自变量不同分类水平在模型中的系数,正负符号表明它们与早餐选择是正比还是反比关系。第六列是瓦尔德检验显著性值,此值小于0.05说明对应自变量的系数具有统计意义,对因变量不同分类水平的变化有显著影响。
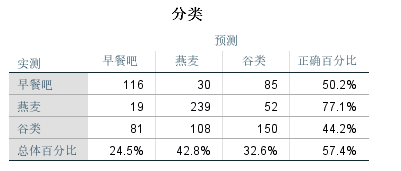
模型在预测燕麦类早餐选择倾向上准确率最高,达到77.1%,其他两个早餐选择的预测略低,模型总体预测准确率为57.4%,表现一般。前面伪R方数据显示,模型对总体变异的解释能力不足,这和总体预测准确率结论也一致。
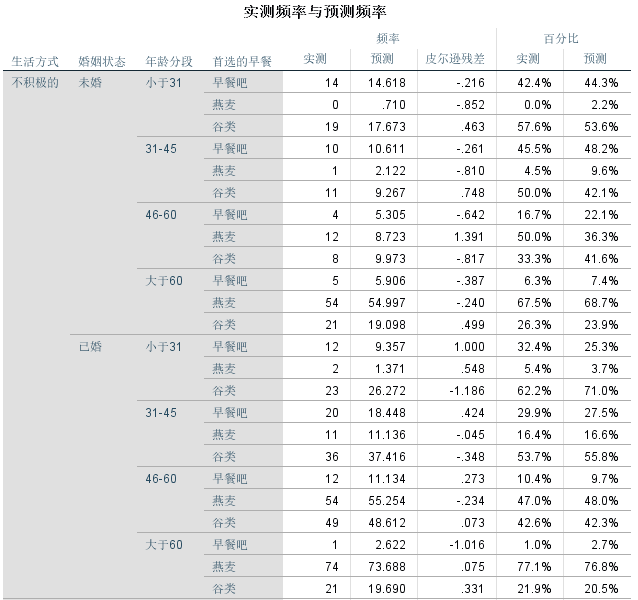
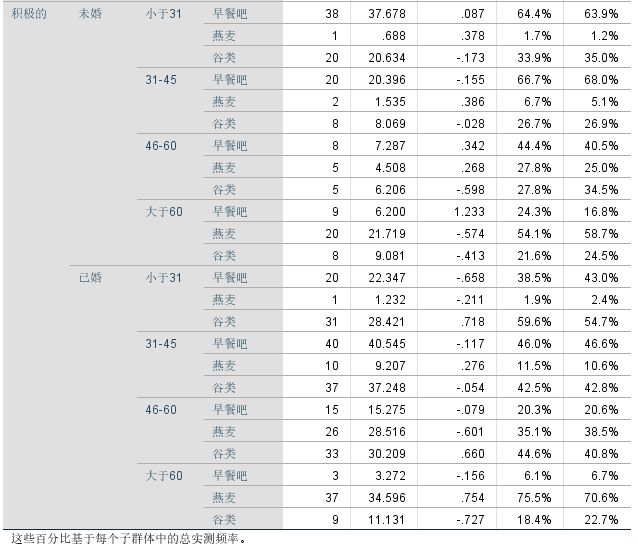
从实测频率和预测频率中可以看到,对各种分类实测预测所占百分比。

原始数据最右侧新增6个变量,依次为EST1_1、EST2_1、EST3_1、PRE_1、PCP_1、ACP_1,分别对应因变量“早餐选择”的三个分类水平(早餐摊、燕麦类、谷物类)的响应概率、预测分类、预测类别概率、实测类别概率。比如第一个个案,他选择谷物类早餐的概率为0.55,在三种选择中数值最大,因此,模型会判定他选择谷物类早餐,这和原始记录的真值一致,说明模型判断准确。