 目录
目录Python全系列 教程
3567个小节阅读:5930.8k
目录


鸿蒙应用开发
C语言快速入门
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night

使用卡方分箱的目的是为了创建更加稳健和有效的预测模型。通过将数据分箱,我们可以确保每个箱子内的数据在目标变量上的分布是相似的,这样可以减少模型在处理数据时的偏差和噪音。此外,分箱还可以帮助我们处理非线性关系,并在一定程度上防止过拟合。
初始化阶段:
首先按照属性值的大小进行排序(对于非连续特征,需要先做数值转换,然后排序),然后每个属性值单独作为一组。
合并阶段:
(1)对每一对相邻的组,计算卡方值。
(2)根据计算的卡方值,对其中最小的一对邻组合并为一组。
(3)不断重复(1),(2)直到计算出的卡方值都不低于事先设定的阈值,或者分组数达到一定的条件(如最小分组数5,最大分组数8)。
值得注意的是,有的实现方法在合并阶段,计算的并非相邻组的卡方值(只考虑在此两组内的样本,并计算期望频数),因为他们用整体样本来计算此相邻两组的期望频数
下图是著名的鸢尾花数据集sepal-length属性值的分组及相邻组的卡方值。最左侧是属性值,中间3列是3个不用类别鸢尾花的频数,最右是卡方值。这个分箱是以卡方阈值1.4的结果。可以看出,最小的组为[6.7,7.0),它的卡方值是1.5
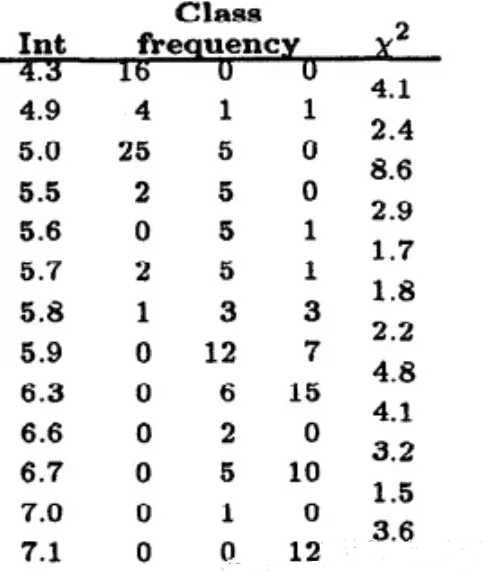
如果进一步提高阈值,如设置为4.6,那么以上分箱还将继续合并,最终的分箱如下图:

卡方分箱除了用阈值来做约束条件,还可以进一步的加入分箱数约束,以及最小箱占比,坏样本率(Bad Rate)约束等
提示
在信用风险建模中,坏样本率通常指的是违约率,即贷款违约的客户在所有贷款客户中的比例。
设置坏样本率的约束可以确保每个箱中坏样本的比例不会过高或过低,这有助于区分不同的风险等级。
Bad Rate:坏样本率,分档内坏样本数 / 分档内全部样本数