 目录
目录Python全系列 教程
3567个小节阅读:5930.1k
目录


鸿蒙应用开发
C语言快速入门
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night

决策树学习的算法通常是一个递归地选择最优特征(选择方法的不同,对应着不同的算
法),并根据该特征对训练数据进行分割,使得各个子数据集有一个最好的分类的过程。这
一过程对应着对特征空间的划分,也对应着决策树的构建。
熵(entropy)表示随机变量不确定性的度量。设X是一个取有限个值的离散随机变量,其
概率分布为
则随机变量X的熵定义为
特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件
下D的经验条件熵H(D|A)之差,即
信息增益大的特征具有更强的分类能力
举个例子:
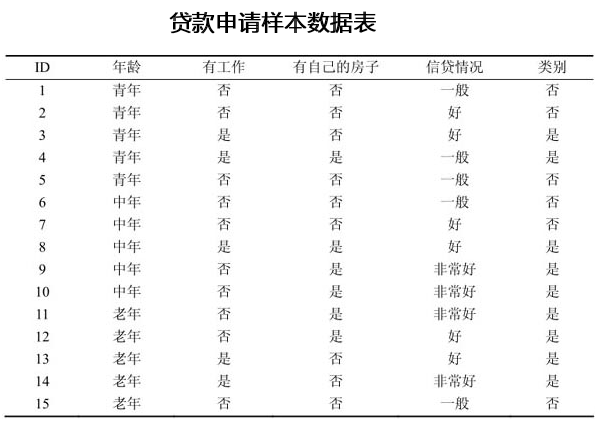

g(D,A~2~),g(D,A~3~),g(D,A~4~)的计算方法类似
信息增益值的大小是相对于训练数据集而言的,并没有绝对意义。当某个特征的取值种
类非常多时,会导致该特征对训练数据集的信息增益偏大。反之,信息增益值会偏小。使用
信息增益比(information gain ratio)可以对这一问题进行校正。这是特征选择的另一准
则。
特征A对训练数据集D的信息增益比g~R~(D,A)定义为其信息增益g(D,A)与训练数据集D关于
特征A的值的熵H~A~(D)之比,即
注意:
决策树生成只考虑了对训练数据更好的拟合,可以通过对决策树进行剪枝,从而减小模型的复杂度,达到避免过拟合的效果
1. 关于决策树,下列说法正确的是:
A 决策树只能解决分类问题
B 决策树只能解决回归问题
C 决策树是自下而上生成的
D 决策树提供了一种展示类似在什么条件下会得到什么值这类规则的方法
2. 关于信息增益与信息增益比,下列说法正确的是:
A 信息增益越大,特征的分类能力越弱
B 信息增益值的大小具有绝对意义
C C4.5在生成决策树的过程中,用信息增益比来选择特征
D 以上说法均不正确
1=>D 2=>C