 目录
目录Python全系列 教程
3567个小节阅读:5931.2k
目录


鸿蒙应用开发
C语言快速入门
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
判别分析的概念和目的
判别分析是一种对观察对象进行分类的统计学方法,它与聚类分析不同,它在分析之前就非常明确观察对象分为几个类别,该分析方法的目的就是从现有已知类别的观察对象中建立一个判别函数来,然后再用该判别函数去判别同质的未知类别的观察对象。比如医生根据胰腺炎的不同类型建立判别函数,就可以在病人入院时快速的判定其为何种类型,进而采取适宜的处理措施。
判别分析的一般形式
y=a1x1+a2x2+……+anxn(a1为系数,Xn为变量)。事先非常明确共有几个类别,目的是从已知样本中训练出判别函数
判别分析的前提条件 (1)样本量应尽可能大; (2)对已知分类或分组(即:因变量)的标准要尽可能客观、准确和可靠,使建立起来的判别函数能起到准确的判别效果; (3)自变量(即:观察指标)和因变量之间要有重要的影响关系,选择自变量时应挑选既有区别性又有重要性的指标,这样可以用最少的变量达到较高的判别能力; (4) 各观察指标变量尽可能服从正态分布; (5) 各观察指标变量应是连续型变量,判断类别或组别变量应是分类变量; (6)所选择的各观察指标变量之间的相关性应较弱,也就是相关性检验不能达到显著水平,并且2个变量之间的相关性在不同的类别或组别中应一致。
导入数据
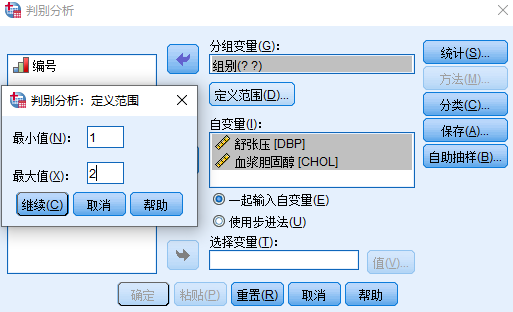
输入变量的方式选择一起输入变量。如果有变量作为筛选的变量可以在选择变量中选择。

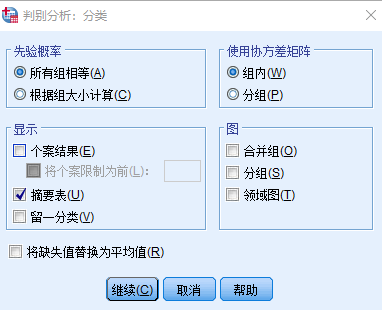
点击“确定”,在输出窗口中查看结果:
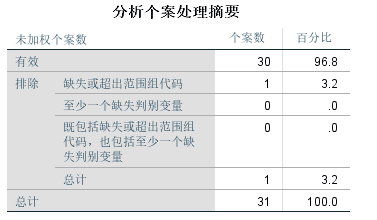
在个案处理摘要表可以看到有效个案数30,所占百分比。缺失或超出范围组代码1。
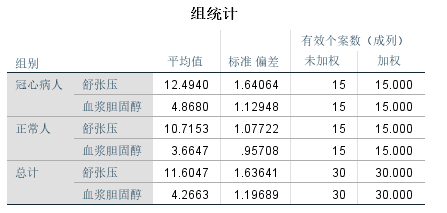
在组统计表中可以看到,冠心病人和正常人的舒张压和血浆胆固醇平均值,我们发现冠心病人的舒张压和血浆胆固醇平均值高于正常人的平均值。
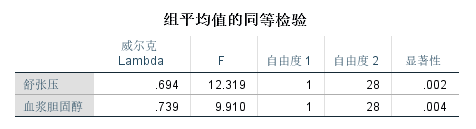
从组平均值的同等检验中可以看到舒张压和血浆胆固醇的显著性都小于0.05。说明冠心病人和正常人之间舒张压和血浆胆固醇平均值是存在显著性差异的。
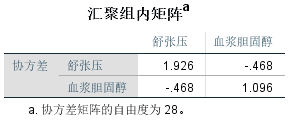
上表是组内协方差矩阵。
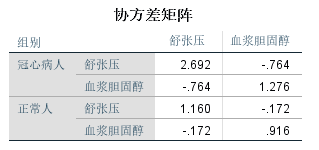
上表是组别协方差矩阵。
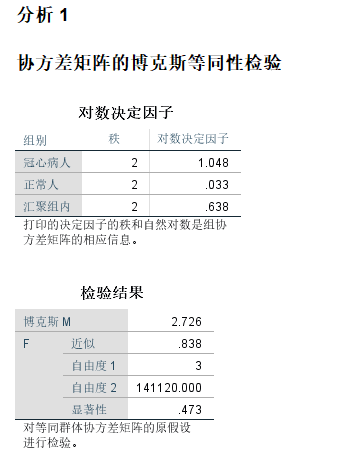
上表协方差矩阵等同性检验结果可以看到,显著性大于0.05,表明对等同群体协方差矩阵的原假设检验成立。
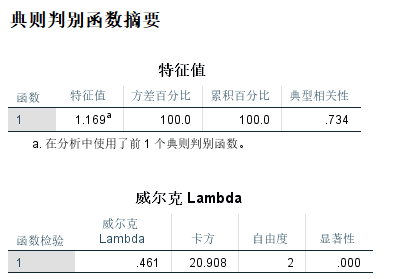
从特征值中可以看到,使用一个函数就可以解释所有方差变异。
威尔克Lambda用来检验函数是否有统计学意义。从显著性可以看到小于0.05,说明函数检验是有统计学意义的。
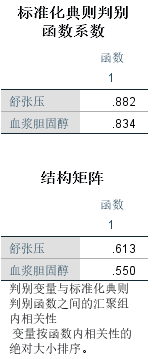
标准化判别函数系数 中可以得到判别函数y = 0.882 * 舒张压+0.834 * 血浆胆固醇
在结构矩阵中是判别变量与标准化典则判别函数之间的汇聚组内相关性,从中可以看到,舒张压对冠心病人的贡献较大。
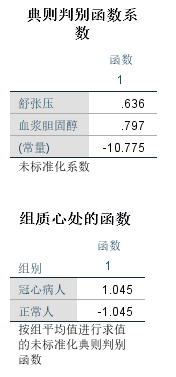
典则判别函数系数是未标准化的系数。从中可以得到判别函数是:y=0.636 * 舒张压+0.797 * 血浆胆固醇-10.775
在组质心处的函数给出两种类别在组质心处的位置,从而判别属于哪种类别。
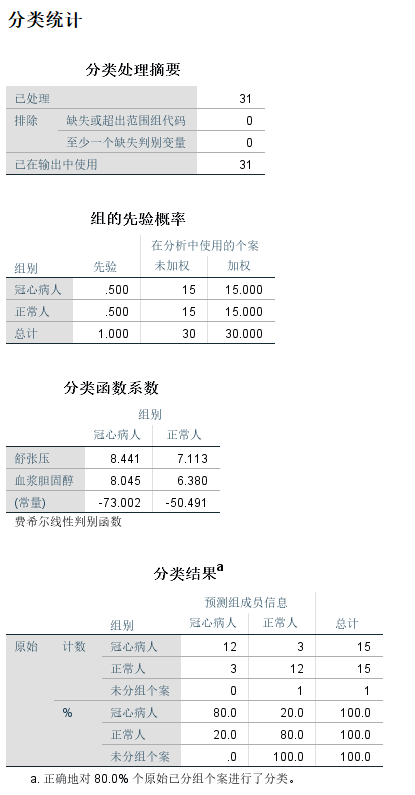
从分类处理摘要可以看到已处理个案数,排除个案数。
从组的先验概率中可以看到,两个类别的先验概率是相等的。
从分类函数系数可以得到分类函数:y(冠心病人)=0.8441 * 舒张压+0.8045 * 血浆胆固醇 - 73.002
y(正常人)=7.113* 舒张压+6.380* 血浆胆固醇 - 50.491
从分类结果表中可以看到,原始总计人数15,冠心病人12,正常人3。对原始分组个案进行分类中冠心病人正确率达到80%,正常人正确率达到20%。